Streaming 101: The world beyond batch
- tags: Bigdata,Flink,Streaming
- source: Akidau, Tyler. “Streaming 101: The World beyond Batch.” O’Reilly Media, August 5, 2015. https://www.oreilly.com/radar/the-world-beyond-batch-streaming-101/.
Streaming: a type of data processing engine that is designed with infinite data sets in mind.⌗
Other common uses of “streaming” that will be avoid in the rest of the post:
- Unbounded data: A type of ever-growing, essentially infinite data set.
- Unbounded data processing: An ongoing mode of data processing, applied to the aforementioned type of unbounded data.
- Low-latency, approximate, and/or speculative results: These types of results are most often associated with streaming engines.
Limitations of streaming⌗
To beat batch at its own game, you really only need two things:
- Correctness: exactly-once requires strongly consistent state.
- Tools for reasoning about time - This gets you beyond batch.Good tools for reasoning about time are essential for dealing with unbounded, unordered data of varying event-time skew.
Event time vs. processing time⌗
Within any data processing system, there are typically two domains of time we care about:
- Event time, which is the time at which events actually occurred.
- Processing time, which is the time at which events are abserved in the system.
Skew always exists between Event time and Processing time.
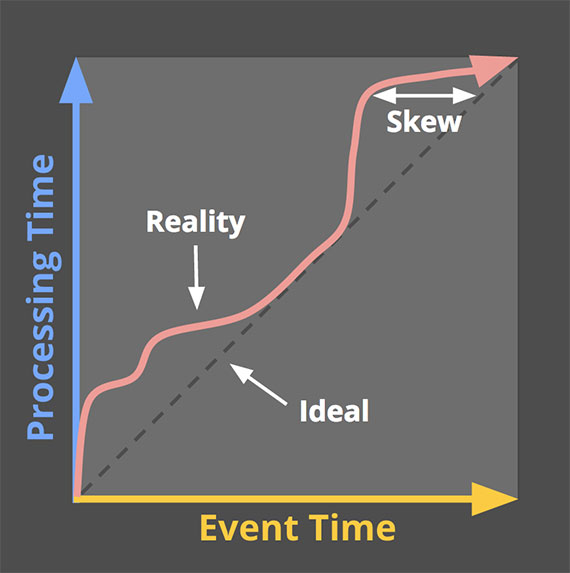
If you care about event times, you cannot analyzer your data solely within the contxt of when they are abserved in your pipeline.
If you care about correctness and are interested in analyzing your data in the context of their event times, you cannot define those temporal boundaries using processing time.
Data processing patterns⌗
Bounded data⌗
Unbounded data — batch⌗
Fixed windows⌗
Sessions⌗
Sessions are typically defined as periods of activity (e.g., for a specific user) terminated by a gap of inactivity.
Unbounded data — streaming⌗
Four groups of dealing data⌗
Time-agnostic⌗
Filtering⌗
Just look at each record as it arrived, and drop the records that we are not interested. We don’t care about the time.
Inner-joins⌗
When joining two unbounded data sources, if you only care about the results of a join when an element from both sources arrive, there’s no temporal element to the logic.